Data Potential Using Web Scraping Python
In an age where data drives decisions and innovation, the ability to extract valuable information from the web is a game-changer. Enter web scraping, a technique that allows you to gather data from websites and transform it into actionable insights. This article dives into the fascinating world of web scraping, demonstrating how Python, a dynamic programming language, empowers you to navigate the intricacies of the web and extract the gems hidden within.
Demystifying Web Scraping
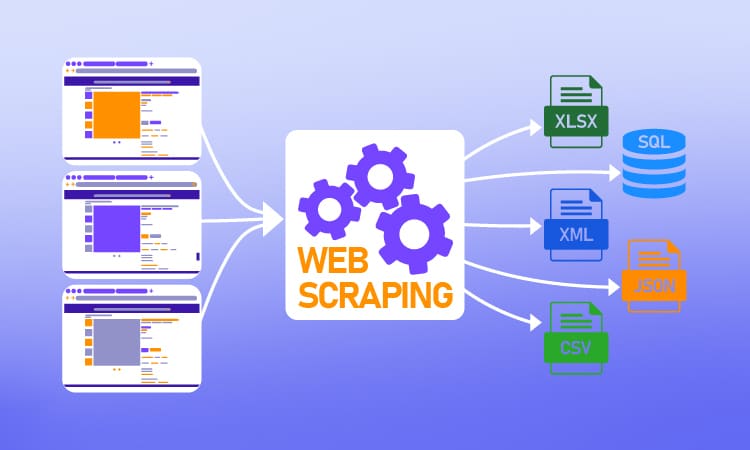
Web scraping, often dubbed “data extraction,” involves automating the retrieval of data from websites. Think of it as sending a digital detective to collect specific information from web pages. Python is your trusted companion, enabling you to orchestrate this process seamlessly.
Python’s Arsenal: Key Libraries for Web Scraping
- BeautifulSoup: As a web scraping library, BeautifulSoup parses HTML and XML documents, unraveling their structures. It acts as your interpreter, translating the website’s language into a format that Python can understand and manipulate.
- Requests: To access web pages, your Python script needs to communicate with servers. The Requests library serves as the messenger, allowing you to send HTTP requests, receive responses, and manage the back-and-forth exchange with the web server.
The Power of Web Scraping
- Competitive Intelligence: Businesses can extract competitor data, analyze pricing trends, and evaluate market demand to fine-tune their strategies.
- Content Aggregation: For content-centric platforms, web scraping aids in collecting articles, blog posts, or other content, keeping your platform fresh and engaging.
- Research Endeavors: Academic researchers can gather data for various studies, from sentiment analysis to tracking social trends and behaviors.
- Personal Curiosity: Curious minds can build custom datasets, analyze trends, or even create art by converting textual data into visual representations.
Ethical Considerations and Responsible Scraping
- Terms of Use: Before scraping a website, review its terms of use. Some websites prohibit scraping, while others might impose restrictions on the frequency and volume of requests.
- Robots.txt: Respect the website’s robots.txt file, a protocol that outlines which parts of the site can be accessed by web crawlers and scrapers.
- Rate Limiting: To avoid overburdening servers, implement rate limiting by introducing delays between requests.
Best Practices for a Seamless Web Scraping Experience
- Understand the Structure: Carefully inspect the webpage’s HTML structure before writing code. Identifying the data’s location simplifies the scraping process.
- Adapt to Changes: Websites evolve. Regularly revisit and update your scraping code to accommodate any modifications.
- Graceful Error Handling: Design your code to handle errors gracefully, mitigating issues like connection failures and missing data points.
- Data Refinement: Extracted data may require cleaning and formatting. Leverage Python’s data manipulation tools to refine raw data into meaningful insights.
Conclusion
Web scraping with Python is an art that transforms the web into an invaluable resource. By harnessing libraries like BeautifulSoup and Requests, you gain the ability to navigate web pages, extract critical information, and turn it into actionable knowledge. Whether you’re seeking business intelligence, pursuing academic research, or satisfying your personal curiosity, web scraping empowers you to explore the boundless data universe. With ethical considerations at the forefront, Python’s capabilities help you unravel insights that were once buried beneath the digital surface, illuminating pathways to innovation and informed decision-making.




